 – CHẨN ĐOÁN HÀM GIẢ THUYẾT LÀ BIAS HAY VARIANCE – CÁCH CHỌN THAM SỐ CHÍNH QUY LAMBDA")
-
Bias và Variance là gì?
- Trước tiên nhìn vào ảnh sau. Ta có đồ thị của 3 hàm giả thuyết khác nhau:
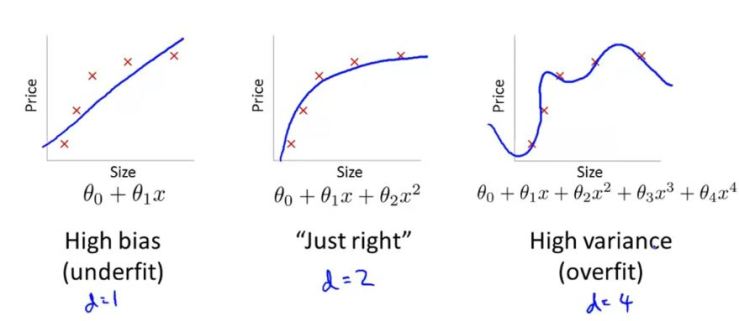
- Nhìn vào hình trên ta có thê hiểu bias là ám chỉ hàm có nhiều khoảng với dữ liệu mẫu và variance là chỉ những hàm vừa vặn với dữ liệu mẫu.
- Nhưng đó là với dữ liệu mẫu. Còn đối với những dữ liệu nằm ngoài tập training thì sao? Theo dõi hình sau:
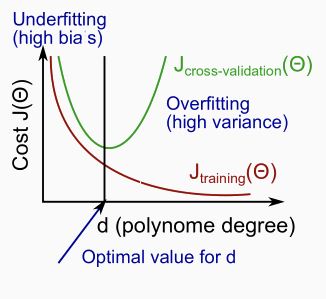
- Các bạn hãy để ý. Trục ngang ( degree of polynomial d) là ám chỉ sự tăng tiến của bậc trong hàm đa thức. Còn trục dọc thì là giá trị lỗi ( tức khoảng cách của giá trị được tính qua hx với nhãn y)
- Nhìn vào đường kẻ J-train ta thấy, bậc của feature càng cao thì độ lỗi càng thấp, nghĩa là hàm giả thuyết càng vừa vặn với dữ liệu mẫu. Ngược lại bậc của feature càng thấp thì giá trị lỗi càng cao.
- Tuy nhiên khi ta nhìn vào đường kẻ J-cv thì lại thấy bậc thấp thì giá trị error cao và bậc cao thì giá trị error cũng vẫn cao. J-cv chính là kết quả những mẫu dữ liệu ko được dùng để training.
- Vậy có thể nói rằng triển khai 1 hàm bậc thấp quá hay cao quá cũng không tốt mà cần sử dụng hàm có bậc bình thường và hợp lý.
- Kết luận:
- Bias là ám chỉ những hàm giả thuyết có lệch cao với cả tập training và tập validate
- Còn Variance là ám chỉ những hàm giả thuyết rất vừa vặn vớt tập dữ liệu nhưng lại có độ lệch cao với tập validate.
- Tính chất:
- BIAS ( underfit):
- Cost Function J-train cao
- Cost Function J-train xấp xỉ bằng Cost Function J-cv
- Đối với hàm số bị coi là BIAS thì càng nhiều dữ liệu training cũng không đem lại nhiều hiệu quả bởi sự sai lệnh của nó lớn
- VARIANCE ( overfit):
- Cost Function J-train thấp
- Cost Function J-cv lớn hơn rất nhiều so với Cost Function J-train
- Đối với hàm số bị coi là VARIANCE thì càng nhiều dữ liệu training cũng không sẽ lại nhiều hiệu quả bởi vì nó có thể tạo ra được một chút sai lệch với dữ liệu mẫu
-
Regularization và Bias/Variance
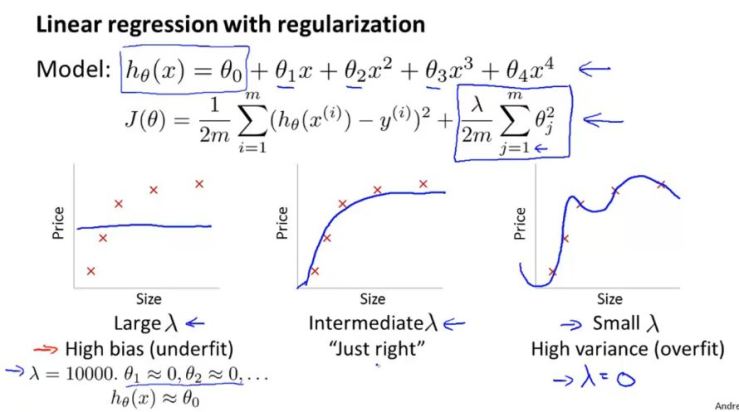
- Nhìn vào hình trên ta thấy. Khi sử dụng chính quy với thuật toán thì việc lựa chọn lambda không tốt cũng có thể dẫn tới underfit hay overfit.
- Với lambda quá lớn thì để minimize Cost Function J bắt buộc các bộ số theta phải cực nhỏ. Điều này có thể dẫn tới hx xấp xỉ bằng giá trị theta0 và gây ra BIAS
- Còn với lambda quá nhỏ thì dường như việc chính quy hóa ko có ý nghĩa, các bộ số theta vẫn tự do và có thể dẫn tới việc VARIANCE
- Vậy làm thế nào để chọn tham số chính quy ( lambda) một cách hợp lý?
- Lựa chọn tham số chính quy – lambda hợp lý
- Sau khi thực hiện Model Select, lựa chọn được hàm đa thức giả thuyết hợp lý ta bắt đầu tính Cost function chính quy trên tập dữ liệu training với bộ số lambda như sau:

- Với mỗi một giá trị lambda thuộc (0, 0.01, 0.02, 0.04, 0.08, 0.16,…,10.24) ta sẽ tìm được các tập theta khác nhau.
- Từ những tập theta tìm được ta lấy chúng để tính Cost function chính quy trên tập dữ liệu CV ( cross validate). Và chọn ra J(cv) nhỏ nhất.
- Từ J(cv) đó ta lấy luôn lambda tương ứng làm giá trị tham số chính quy cho thuật toán.
- LÀM GÌ TIẾP THEO
- Bây giờ hãy quay lại yêu cầu đề bài ban đầu.
- Giả sử bạn training một tập dữ liệu và triển khai được một thuật toán. Tuy nhiên khi bạn có một đầu vào mới ( dữ liệu không có nhãn) và sử dụng thuật toán đó để tính output. Nó lại cho ra một kết quả không tốt ( thậm chí có lỗi lớn). Vậy bạn sẽ làm gì tiếp theo để cải thiện lại thuật toán của mình?
- Bạn cần xác định hàm đó đang bị BIAS hay VARIANCE
- 1. Lấy thêm nhiều dữ liệu mẫu có nhãn để training lại
- 2. Thu gọn lại bớt các tính năng đặc trưng của dữ liệu
- 3. Mở rộng thêm các tính năng đặc trưng của dữ liệu
- 4. Tạo thêm các tính năng đặc trưng đặc biệt từ các tính năng có sẵn ( như là bình phương giá trị 1 tính năng để tạo ra đa thức)
- 5. Tăng giá trị tham số chính quy ( lambda)
- 6. Giảm giá trị tham số chính quy ( lambda)
Đăng bởi Bạch Tuấn
Machine Learning Tùy Bút
Xem tất cả bài viết bởi Bạch Tuấn

