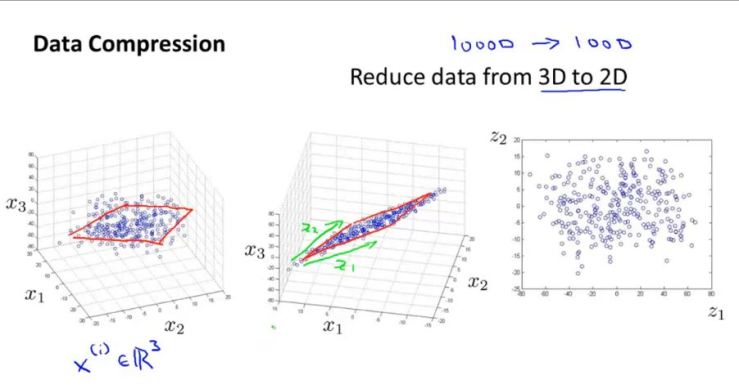
- Khác với Supervised learning, Unsupervised learning là kiểu học tập dựa trên những dữ liệu không có nhãn, hay còn gọi là chưa có output. Những thuật toán này thường là giải quyết những bài toán như gom nhóm, tập hợp các đối tượng có cùng đặc điểm, phân cụm…
- K-Means Algorithm
- Đây là một thuật toán gom cụm các điểm dữ liệu. Thuật toán này hoạt động dựa trên việc vecto hóa các cấu trúc, đặc trưng của dữ liệu trong một không gian R có n chiều. Sau đó gom các điểm tụ tập riêng của từng nhóm dữ liệu thành từng cụm
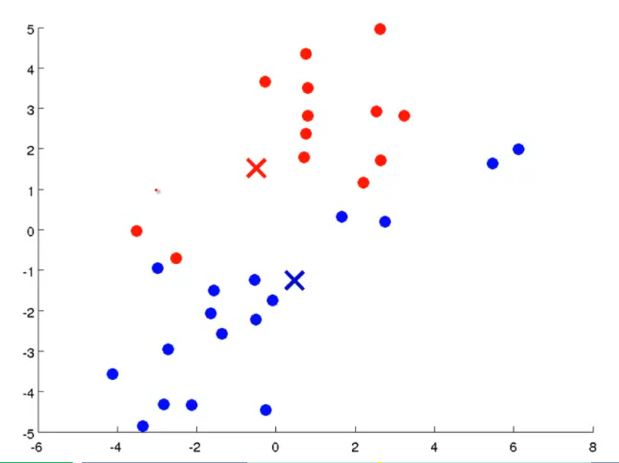
- Ví dụ ta có 1 tập hợp các điểm dữ liệu và được yêu cầu gom thành 2 nhóm khác nhau:
- Vì là chia thanh 2 cụm khác nhau nên ta sẽ chọn random lấy 2 điểm bất kỳ trong không gian trên ( điểm X màu xanh lam và màu đỏ), và chúng được gọi là cluster centroid
- Tiếp đến ta sẽ chia đôi tập dữ liệu trên bằng cách: Những điểm nào gần cluster centroid màu xanh lam sẽ là thuộc cụm xanh lam. Những điểm nào gần cluster centroid màu đỏ sẽ thuộc cụm màu đỏ
- Tính khoảng cách giữa 1 điểm a và b thì dùng norm 1 bình phương. P = ||a-b||^2
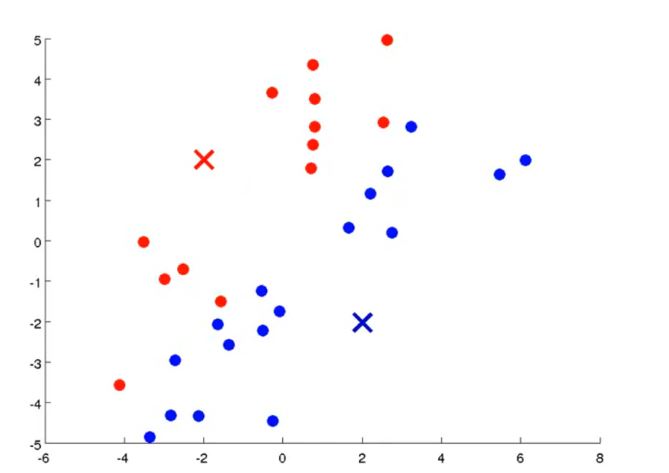
- Sau khi có được 2 cụm ta sẽ update lại vị trí của các cluster centroid bằng cách lấy giá trị trung bình cộng của tất cả các point thuộc cụm đó gán thành cluster cenroid mới.
- Với 2 vị trí mới của cluster centroid. Lúc này đi lại tiếp tục làm lại động tác phân cụm. Tức là trong tất cả những điểm dữ liệu trên, điểm nào gần cluster centroid xanh lam lại về thành 1 cụm, điểm nào gần ông màu đỏ lại về 1 cụm
- Bây giờ ta lại tiếp tục update vị trí 2 ông cluster centroid. Nhớ là update bằng cách lấy trung bình cộng vị trí của tất cả các point trong cụm nhé.

- Sau khi update thì ta thấy 2 ông này đang di chuyển dần dần về phía trung tâm rồi đó.
- Ta tiếp tục phân cụm lại bằng cách điểm nào gần ông xanh lam là cụm xanh lam, gần ông đỏ là cụm ông đỏ.

- Sau khi update vị ví của 2 ông centroid. Ta lại phân cụm lại bằng cách gần ông nào thì là cụm đấy.
- Cuối cùng sau khi nhận ra sự update không thay đổi về phần tử, hoặc vị trí cluster centroid đối vơi từng cụm. Thì đó là lúc chúng ta gom cụm xong.
- TỔNG QUÁT K-MEANS:

- Bước 1: Ramdom vị trí của các cụm. K là số cụm cần gom thì ta có K điểm cluster centroid.
- Bước 2: Phân cụm. Chay vòng lặp từng điểm một. Điểm nào gần điểm cluster centroid nào thì phân nó về cụm đấy.
- Bước 3: Update lại vị trí của các cluster centroid. Bằng cách xài trung bình cộng các điểm trong cụm.
- Bước 4: Lặp lại bước 2 và 3 cho đến khi sự phân chia cụm hay update vị trí của cluster centroid không thấy sự thay đổi.
- COST FUNCTION
- Chúng ta đã biết cách phân cụm và tìm các điểm cluster centroid của từng cụm. Tuy nhiên vì ban đầu chúng ta random lấy các điểm cluster centroid nên cùng 1 tập dữ liệu, với các lần lặp thuật toán khác nhau nên ta sẽ tìm được các điểm cluster centroid khác nhau và các cụm khác nhau. Vậy làm thế nào để lấy kết quả tốt nhất.
- Người ta xây dựng một cost function. Với mỗi một bộ kết quả ta thu được ( 1 bộ kết quả bao gồm điểm cluster centroid của từng cụm và các điểm data trong cụm đó). Ta lấy tổng số khoảng cách của từng điểm đến cluster centroid của cụm chứa điểm đó cộng vào rồi chia trung bình cộng ( chia cho m) và gán nó vào J. Bộ kết quả nào cho ra kết quả J đạt min thì ta được điểm cluster centroid và cụm phân loại tối ưu nhất.
- Công thức:

- c là ký hiệu cụm của phần tử x. Ví dụ c(1) = 2. Thì là x1 thuộc cụm 2. Cụm sẽ chạy từ 1 đến k
- x là ký hiệu điểm dữ liệu.
- µ là ký hiệu cluster centroid của cụm mà điểm x đang trực thuộc
- Khi J đạt min thì ta được bộ kết quả c và µ tối ưu nhất.
- KHỞI TẠO GIÁ TRỊ K VỚI 1 TẬP DỮ LIỆU ( SỐ LƯỢNG CỤM)
- 1. Nên khởi tạo số lượng cụm. Tức K nhỏ hơn số lượng data point. K < m
- 2. Nên khởi tạo các cluster centroid là những điểm dữ liệu ngẫu nhiên. µ1 có thể là x(1), µ2 có thể là x(10), uk có thể là x(m)…
- Chạy K-Means nhiều lần sau đó chọn các bộ kết quả có Cost J thấp nhất để có được phân cụm tối ưu.
- Ngoài ra đối với việc lựa chọn số cụm cụ thể cho 1 tập dữ liệu thì thực sự không có cách nào được định nghĩa chính xác. Bởi càng nhiều cụm thì cost function J càng nhỏ. Người ta thường dựa vào thực tế đặc điểm của data mà lựa chọn số cụm phù hợp.
Đăng bởi Bạch Tuấn
Machine Learning Tùy Bút
Xem tất cả bài viết bởi Bạch Tuấn